tldr;
By integrating Sentry data with New Relic dashboards and Anodot anomaly detection, you can get both deep analysis of your React Native app’s errors AND easy to digest, high level dashboards/alerts that quickly tell you what’s going on. No sacrifices or tradeoffs. Want to jump to the technical bits? Skip to here. Setup instructions for your own project are available in the GitHub README.
Congratulations! You just built an app that totally revolutionizes the way humans interact with one another and are poised to become the next Mark Zuckerberg. Your app doesn’t just use all the buzzwords of 2016, it creates new ones. And because you use React Native, your app is ready to ship for Android and iOS from day one.
Except that your app is shit. Not necessarily because you're a bad developer (you might be, but I don't know you), but because it’s a brand new app and all new code has tons of bugs.
That your app is full of bugs isn’t the problem. That’s normal. The problem is that you have no way of knowing just how buggy it is if you don’t monitor errors, crashes, business KPIs, and gather general BI. The fundamental principle of devops is that your work isn’t finished when you ship, it’s just getting started.
Enter Sentry
Fortunately for us, there are quite a few monitoring tools out there. These usually come with an SDK you can add to your app that reports errors or events of some kind to their server, and a UI (and hopefully API) for you to keep track of what’s going on in the wild. For a variety of reasons, our team (the mobile team at Wix) likes Sentry. It’s fairly easy to work with, easy to set up, and has nice support for JS code. We use it inside React Native to report errors, warnings, and various events inside the JS portion of our React Native app.
The Problem
Remember that bit I mentioned about how monitoring tools usually come with a UI and API for you to keep track of your errors? Just collecting data isn’t very helpful if you don’t look at it. And if you have a flood of data, you will have a tendency to ignore it. You must have a good way of filtering, aggregating, and visualizing the data so you can digest it quickly. You want some kind of dashboard you can put on the wall that you’ll see all the time. It should help you immediately answer some questions, like:
- That feature we just released - did it cause a jump in errors?
- Are errors trending up or trending down over the last few hours? days? weeks?
- How many people are using your app?
And if your app is as big as ours at Wix, and has multiple teams working on different features/modules within it, you want to be able to filter the events by relevance to your team. So to every one of those questions, add the qualifier “in my portion of the app’s code”.
Unfortunately, I found that Sentry’s web app wasn’t great at answering these questions. It appears more geared toward answering questions specific to a single issue (a group of events that their algorithm considers to be caused by the same scenario/error):
- What version of the app did this issue start happening on?
- How often does it occur?
- How is it distributed between platforms (ios vs android) and users?
- How many users did it affect?
- Is it becoming more common or less common?
- And finally, how can I fix it? (Stack trace)
In other words, Sentry’s web app is focused on drilling in to a specific issue/error and studying the events that occurred that match that issue. That’s a really important thing to have, but it’s only half of what I need.
When I walk into my office in the morning, I want to see a big number on the wall that represents our error count in the last hour. I’d like to see a graph that shows the error trend in the last few hours compared with last week at the same time (since usage is often cyclical by day of week). And maybe throw in a longer term trend graph, because, why not? I also like to see some color. Maybe green when things are good, yellow when they're so-so, and red when they're positively SCARY. I don't want to have to look at my monitor too closely, I want it to jump out at me every time I walk by it.
Enter New Relic
Here at Wix, we’re big on New Relic for monitoring. It’s a pretty robust tool, and we use it on our servers, our web clients, and in the native code of our mobile app for monitoring all kinds of things. Among other things, it allows us to build nice dashboards we can plaster on monitors all around our offices that give us broad overviews of whether we’re in good shape or not.
Oh, and New Relic even has a mobile app for viewing your dashboard as well!

(Photo credit: New Relic, Inc)
How cool is that? I can obsessively monitor my app's production performance anytime, like when I'm sitting on the bus, talking to my mom, or having sex. Seriously, how great is that? (Just kidding. I’m a nerd, we don’t have sex.)
What I’d really like, then, is a way to get my Sentry data into New Relic so that I could build a dashboard like the one you see above for my JS errors and warnings.
What About Alerts?
Another tool we like to use at Wix is Anodot, an "anomaly detection" tool. That's a fancy way of saying that you report data to them, and (among other things) their algorithms monitor that data and learn to identify the trends they follow. You can set up alerts that will notify you if you when the trends are broken (anomalies), which means you might get notified if you have a jump in errors, for example. They also have dashboard support, but I'm mostly interested in their alert system at this point. After all, I don't really obsessively check the New Relic app while I'm having sex. An email, though, well...that would get my attention. If only there was a way to get my Sentry events into Anodot...
The Solution
Rule number one of using third party services: never put your data anywhere you can’t access via an HTTP API of sorts.
It took me only a few hours to whip up a script that uses the Sentry API to retrieve the last five minutes’ worth of data, filter and aggregate it, and report it to New Relic and Anodot using their respective APIs. Then another few hours to build my dashboards and alerts, and I was done.
Just kidding, I was just getting started. How was I going to run that script reliably? More importantly, how were YOU going to run that script if it had all my own configuration hard-coded everywhere?
(Speaking of basic rules of software development: for every hour you spend hacking together some cool trick that does exactly what you want, budget five hours for making that POC generic, stable, and reliable enough for use in more than your very specific use-case.)
So I spent a while working on that script to turn it into something more robust and generic. It’s still a work in progress, and I welcome your assistance in the form of issues and PRs on GitHub. You can head over to the README there for the full instructions on how to get started, but here’s the basic idea:
Create a simple node web server with the following snippet:
const monitor = require('sentry-monitor'); //this should be obvious, but first you need: npm install --save sentry-monitor
const config = {
SENTRY_AUTH: 'auth_token_for_sentry_api', //head to Sentry's docs to find this
NEW_RELIC_AUTH: 'new_relic_insert_key', //NR's docs will explain how to generate this
NEW_RELIC_ACCOUNT_ID: 'this_is_your_nr_account_id', //appears in pretty much every url inside your NR account
ANODOT_AUTH: 'auth_token_for_anodot_api', //Anodot's docs explain how to get this
WSM_AUTH_KEY: 'optional_secret_key_for_security', //see below for explanation
org: 'your_sentry_org_name',
project: 'your_sentry_project_name',
filters: [
{
name: 'TeamA',
searchTerms: ['items I want to see', 'MORE_ITEMS']
},
{
name: 'TeamB',
searchTerms: ['data in filters can overlap!']
}
]
};
const app = monitor(config);
app.listen(3000, () => console.log('Listening on port 3000'));Create a cron job that uses curl to send a POST request to your server every five minutes:
*/5 * * * * curl http://localhost:3000/?debug=true -X "WSM_AUTH_KEY: optional_secret_key" -H POSTThe debug query parameter tells sentry-monitor to not actually send any data anywhere, and instead to log it to the console
and return the data in the response. After you do enough dry runs that you're confident your config is correct, don't forget to remove the
query parameter.
Security Note: you need the WSM_AUTH_KEY header if you're going to host the web server on a different server than the cron job and expose the web server publicly. The web server will reject any request that doesn't come with the secret key you set. If you do this, make sure you keep your key secret! If you are not exposing the web server to the outside but instead are hitting it from the same server, you can omit this header.
Why So Complicated?

Why did I do it this way? Why didn’t I just keep my first draft of the script and start it on a server with a setInterval of five minutes?
Because I want reliable monitoring. At Wix, we have lots of prebuilt infrastructure for deploying reliable web servers with redundancy and I wanted to harness that infra. It's a basic principle of server development that you cannot set jobs on web servers that are supposed to be deployed with redundancy. If you do, you'll quickly have more than one server running the job without you realizing it. In our case, that would result in duplicate data.
And consider what happens when I modify the code and want to deploy an update. If I had a script that just ran every five minutes,
restarting the script would interrupt the interval calculation. Then I'd end up with duplicate data for part of one five minute period. I have more than enough errors in my app without my monitor falsely inflating the number, thank you very much.
With the web server approach, I have a stable server cluster running my monitoring tool, integrated with our company's existing monitoring and system infrastructure, and I can deploy changes to it with no downtime and no hiccups to the interval. It runs every exactly every five minutes one some (probably virtual) server or another...somewhere. I just deploy my updates and they're picked up the next time the job runs.
So Why Not Just Use New Relic?
If you got to this point without skipping this should be obvious, but I’m putting this here because people keep asking me this question. Why do I need Sentry at all if New Relic and Anodot are such hot stuff? Why not just report to them directly from my application?
Because I like Sentry. I like the in-depth view of issues, I like the way they are easy to integrate, and I don’t want to have twice as much traffic between my users’ mobile devices and monitoring servers. I like being able to see that there's something wrong from my New Relic dashboard or an Anodot alert and then follow the link to the Sentry issue page, where I can begin to understand why this issue is happening and what I can do about it.
That's why. Ok?
Now stop asking silly questions.
Results
A picture's worth a thousand words, right?
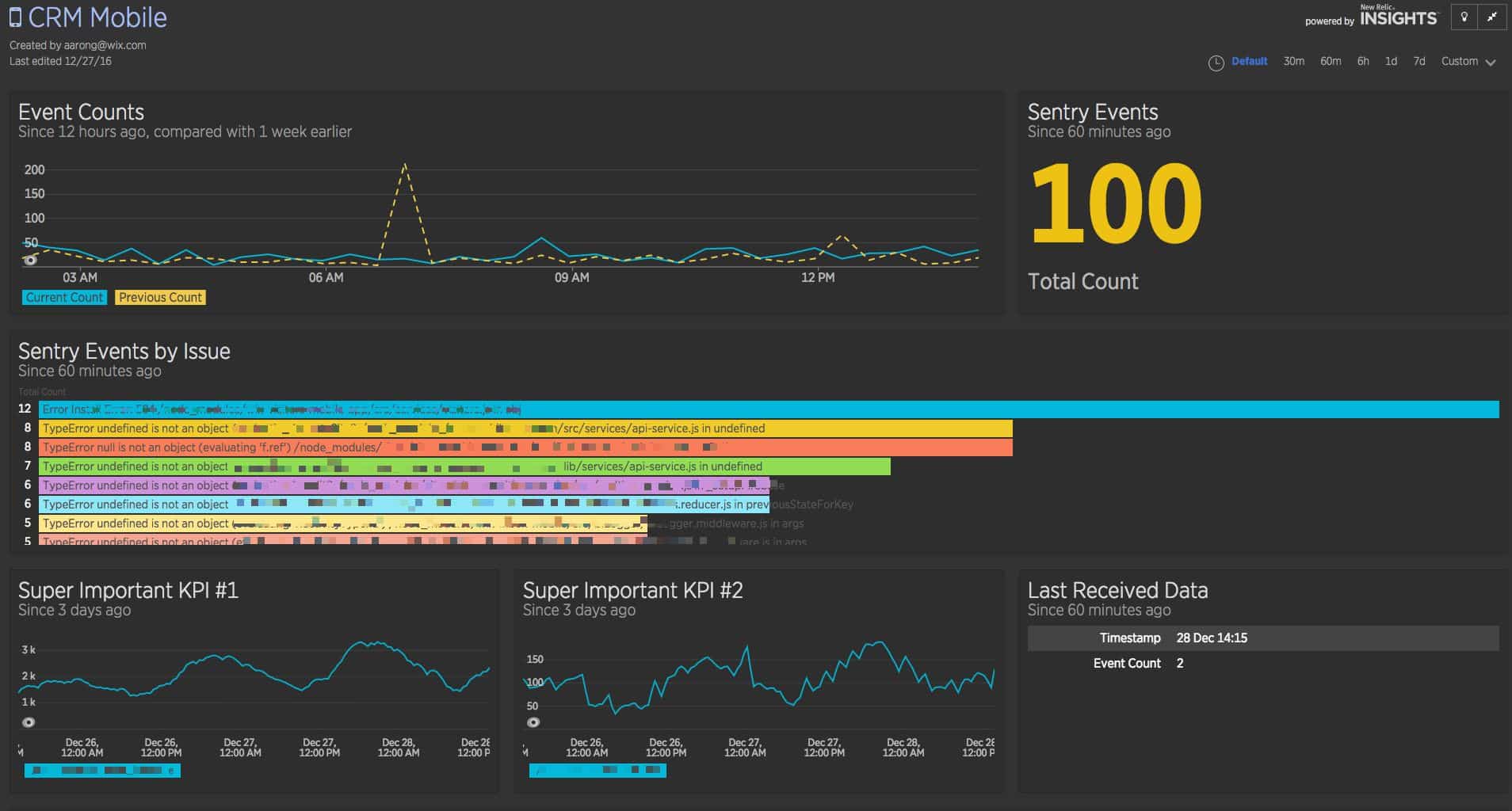
That's my actual dashboard. I measure Super Important Stuff TM
Next Steps
Like any good open source project, this thing is just getting started. Here’s my current roadmap:
- Better test coverage
- Cleaner, more maintainable code
- Multi-project support - we have more than just one project in our Sentry organization. The config should support multiple projects, each with their own filters
- Better logging and error handling
Want to help out? Try it yourself, and then head over to the GitHub repo and report issues or open PRs. Your contribution is most welcome. Questions? Comments? Tweet to me @aaronjgreenwald.
P.S. I don't actually check my email during sex either. That is, I wouldn't if I wasn't a nerd and this wasn't just a theoretical question. Whatever.